В предыдущих статьях ([1], [2], [3], [4]) были показаны реализация мониторинга и управление температурой с помощью устройств NetPing и программных пакетов MRTG, Cacti и Zabbix. Несмотря на то, что эти системы мониторинга способны удовлетворить потребности самого требовательного администратора, существуют также и другие системы мониторинга.
В нашей стране большой популярностью пользуется система мониторинга Nagios, к плюсам которой можно отнести её гибкость (по этому параметру она превосходит даже Zabbix), а к минусам - относительную сложность её конфигурирования.
Если в вашей компании используется Nagios, и вам была поставлена задача настроить отслеживание температуры в помещениях с помощью устройств NetPing TS v2 производства компании «Алентис Электроникс» или вы просто хотите попробовать освоить Nagios, то эта статья для вас. Ниже будет показано, как настроить мониторинг температуры с помощью Nagios.
Как обычно начальные условия:
- Сервер мониторинга под управлением Ubuntu 9.04 Server, который имеет IP-адрес 192.168.2.230;
- Устройство NetPing TS v2, имеющее IP-адрес 192.168.2.10, и SNMP-Community SWITCH, доступ к которому разрешён, как минимум, с сервера мониторинга.
Первым шагом установим Nagios:
apt-get install nagios3 exim4-daemon-light
Exim понадобится для отправки оповещений по e-mail. В процессе установки потребуется скачать около тридцати мегабайт необходимых пакетов.
После установки надо создать файл /etc/nagios3/htpasswd.users и добавить в него пользователя root. Сделаем это:
htpasswd -c /etc/nagios3/htpasswd.users root
Теперь мы можем открыть в браузере страницу "http://192.168.2.230/nagios3/" и авторизоваться в системе, используя логин "root" и пароль, который был введён на предыдущем шаге.
Однако веб-интерфейс системы предназначен только для просмотра состояния устройств. Все настройки хранятся в конфигурационных файлах. Поэтому пока оставим в покое интерфейс и приступим к конфигурации системы. Первым делом, нам нужно описать новый хост для мониторинга, для этого создадим файл mcedit /etc/nagios3/conf.d/host-netping.cfg следующего содержания:
define host {
# Имя хоста для использования внутри системы
host_name netping
# Имя хоста, показываемое пользователю
alias NetPing TS v2
# IP-адрес или DNS-имя хоста для мониторинга
address 192.168.2.10
# Основной используемый шаблон
use generic-host
}
Теперь нам нужно определить к какой группе относится этот хост. Создадим для таких хостов отдельную группу: «netping-devices», для этого открываем в редакторе файл /etc/nagios3/conf.d/hostgroups_nagios2.cfg и дописываем в конец следующие строки:
define hostgroup {
# Имя группы для использования внутри системы
hostgroup_name netping-devices
# Имя группы, показываемое пользователю
alias NetPing TS v2 Devices
# Хосты - члены этой группы. Перечисляются через запятую
members netping
}
Далее опишем команды для мониторинга устройства, для этого создадим файл /etc/nagios-plugins/config/netping.cfg, следующего содержания:
define command{
command_name term_on_sensor1
command_line /usr/lib/nagios/plugins/check_snmp -H '$HOSTADDRESS$' -C '$ARG1$' -o 1.3.6.1.4.1.25728.50.8.1005 -l 'Term on sensor1' -u 'degree' -w '$ARG2$' -c '$ARG3$'
}
define command{
command_name term_on_sensor2
command_line /usr/lib/nagios/plugins/check_snmp -H '$HOSTADDRESS$' -C '$ARG1$' -o 1.3.6.1.4.1.25728.50.8.1017 -l 'Term on sensor2' -u 'degree' -w '$ARG2$' -c '$ARG3$'
}
Здесь показаны команды только для двух датчиков, однако, их может быть и больше. Соответствующие OID'ы вы можете уточнить в документации на устройство.
Теперь остаётся связать эти команды с нашим новым хостом или группой хостов. Пока будем связывать с конкретным хостом. Для этого открываем в редакторе файл /etc/nagios3/conf.d/services_nagios2.cfg и дописываем в конец строки:
define service {
# Имя хоста, за которым будем следить
host_name netping
# Имя этого сервиса
service_description TERM1
# Команда проверки
# Передаваемые ей параметры разделяются восклицательным знаком
# В нашем случае параметры обозначают (см. описание команды в netping.cfg):
# 1. SNMP Community
# 2. Значение, при превышении которого ситуация будет считаться опасной (Warning)
# 3. Значение, при превышении которого ситуация будет считаться критической (Critical)
check_command term_on_sensor1!SWITCH!28!29
# Используемый шаблон
use generic-service
# Интервал между проверкой и отправкой оповещений
notification_interval 60
# Время, когда хост должен быть доступен
notification_period 24x7
# Список уровней событий, для которых будут отсылаться оповещения
notification_options w,u,c,r
}
define service {
host_name netping
service_description TERM2
check_command term_on_sensor2!SWITCH!24!27
use generic-service
notification_interval 60
notification_period 24x7
notification_options w,u,c,r
}
Далее открываем в редакторе файл /etc/nagios3/conf.d/contacts_nagios2.cfg, находим секцию с описанием пользователя root и указываем корректный e-mail для отправки сообщений.
Для проверки правильности написания конфигурационных файлов нужно выполнить команду:
nagios3 -v /etc/nagios3/nagios.cfg
В ходе работы команды будет выведена информация о проводимых проверках, и в самом конце будет выведена итоговая информация. Она должна быть такой:
Total Warnings: 0 Total Errors: 0 Things look okay - No serious problems were detected during the pre-flight check
Если у вас не так - ищите ошибки в настройках. После того как все ошибки найдены, и проверка показывает их отсутствие нужно перезапустить сервис Nagios:
invoke-rc.d nagios3 restart
После этого Nagios начнёт отслеживать температуру на заданных датчиках. Проверить это можно через веб-интерфейс, открыв страницу «Host Detail» -> «netping» -> «View Status Detail For This Host». Должна открыться примерно вот такая картина: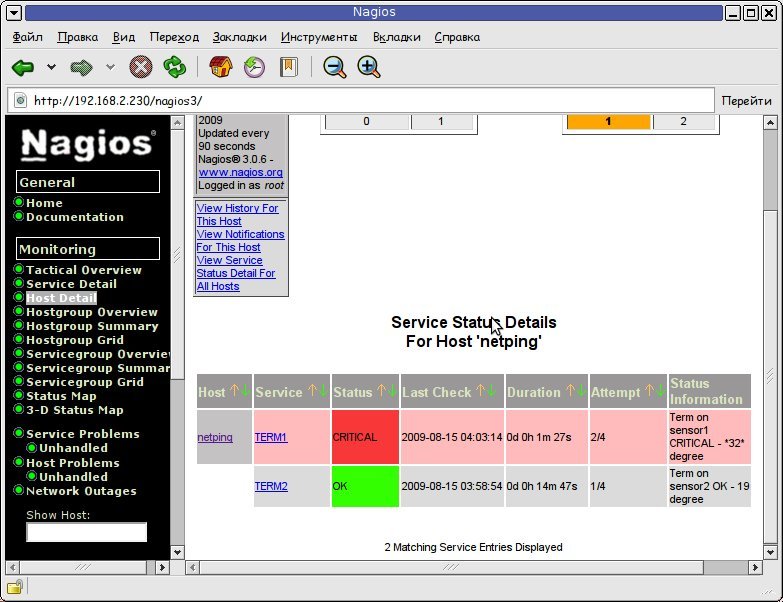
На приведённом выше скриншоте видно, что на втором сенсоре у нас всё отлично, а вот на первом - критический перегрев. Кроме отображения в веб-интерфейсе на e-mail администратору будут приходить сообщения следующего содержания:
***** Nagios ***** Notification Type: PROBLEM Service: TERM1 Host: NetPing TS v2 Address: 192.168.2.10 State: CRITICAL Date/Time: Sat Aug 15 04:05:24 MSD 2009 Additional Info: Term on sensor1 CRITICAL - *31* degree
Также для обработки критических ситуаций можно использовать самописные скрипты, которые будут включать/отключать оборудование, слать оповещения по SMS или через Jabber и выполнять другие действия. Подробнее об этом можно прочитать в официальной документации Nagios.
На этом всё. Приятной работы!
P.S. Статья написана по просьбе «Алентис Электроникс» и так же опубликована на сайте компании.
P.P.S. Отдельное спасибо Фроловой Марии за корректировку статьи.